

Introduction
Imagine this: you hired 10 specialists (an architect, a coder, a tester, an analyst). You gave each of them detailed 1000-line instructions. And instead of coordinated work, you got chaos: one reads the same document 6 times in a row, another ignores tasks and invents their own, a third reports completion without even starting the work. Welcome to my month of working with AI agents.
If you, like me, have spent hours debugging AI agent prompts, seen infinite loops burning through tens of thousands of tokens, and code with placeholders that still doesn’t work, then this story is for you.
Every tool allows you to configure agents in its own way, creating detailed instructions for agent behavior and direction. I used Kilo Code, the most popular application for using openrouter,a fork of Roo Code that, judging by token usage on OpenRouter, is three times as popular. It allows having multiple modes, or agents. By default, there are orchestrator, architect, coder, debugger. You can rewrite instructions for all of them, and add any new agents. This was appealing, because I believed in the mantra of prompt engineering: “a good prompt solves everything”. I was convinced that by creating perfect instructions, I would achieve AI autonomy and quality.
My goal was ambitious: to completely exclude myself from the “human in the loop” role. I dreamed of a system where I just set the task, and an army of smart agents writes code, tests, documentation, and deploys the result itself. I was tired of manually nudging the AI, seeing its stupid mistakes, from non-working code with placeholders to complete ignoring of business logic.
I spent a month on a crusade for the perfect system, built two complex frameworks, and then painfully deleted everything, arriving at an unexpected and disappointing conclusion that, I hope, will save you weeks of work.
Connect on social networks:



The Grand Construction: Dream Architecture
I was obsessed with the idea of full automation. My system wasn’t just a set of prompts, but an entire operating system for AI development. At the top stood the MAIN Orchestrator, the brain of the entire operation, which evaluated task complexity and launched a multi-phase pipeline.
Under my command was an entire army of agents:
Researcher-agentscanned the project (sometimes I even collected the entire repository into oneall_files_as_txt_read_only.txtfor speed) and created a JSON report about files.Architectdrew architecture and Mermaid diagrams based on the report.Docs-writerandTODO-writercreated detailed specifications and broke them into task plans indocs/planing/DD.MM.YY/.Surgical-coderandTDD-testerwrote code and tests.Postmortem-analystanalyzed completed tasks and extracted insights intodocs/project_insights.md.And finally,
Pipeline-executor, which ran myquality_gate.shscript for linting, testing, building, and deploying.
I even provided an ESCALATION protocol: any agent that couldn’t handle a task or saw it was more complex than it initially seemed could pass an unsolvable problem back to the orchestrator with a re-evaluate_complexity task.
Later I developed this idea into a framework where the orchestrator created a formal “Mission Brief” in YAML format before each task, and when delegating, it instructed agents to strictly follow the format MAIN GOAL -> YOUR SUB-TASK -> SCOPE LIMITS -> RELEVANT FILES. This was an attempt to achieve maximum predictability. On paper, this looked like a perfect, autonomous mechanism.
The diagram shows 4 work phases: project research → architectural planning → phased implementation with TDD → automated Quality Gate and insight collection. The orchestrator coordinates all agents through a single Mission Brief.
┌─────────────────────┐
│ USER REQUEST │
└──────────┬──────────┘
│
▼
┌────────────────────────────────────────┐
│ ⚡ ORCHESTRATOR (Complexity Router) │
│ ├─ Create TASK_NAME + MISSION BRIEF │
│ └─ Classify: L1/L2/L3/L4 │
└──────────────────┬─────────────────────┘
│
▼
┌────────────────────────────────────────┐
│ 🔍 RESEARCHER-AGENT │
│ ├─ Read key files │
│ ├─ Identify modification_targets │
│ └─ Output: JSON report (SOURCE TRUTH) │
└──────────────────┬─────────────────────┘
│
▼
╔═════════════════════════════════════════════════════╗
║ PHASE 1: ARCHITECTURAL PLANNING ║
╚═════════════════════════════════════════════════════╝
│
┌──────────────┼──────────────┐
│ │ │
▼ ▼ ▼
┌──────────────┐ ┌─────────────┐ ┌──────────────┐
│ 🤔 DEEP- │ │ 🏗️ ARCHITECT │ │ 📚 DOCS- │
│ THINKER │ │ Design + │ │ WRITER │
│ Strategic │ │ Mermaid │ │ Spec │
│ Brief │ │ Flows │ │ Details │
└──────┬───────┘ └──────┬──────┘ └────── ┬──────┘
│ │ │
└─────────┬───────┴─────────────────┘
│
▼
┌──────────────────────┐
│ 📝 TODO-WRITER │
│ Break into subtasks │
└──────────┬───────────┘
│
│ [CHECKPOINT: Plan Validation]
│
▼
╔═════════════════════════════════════════════════════╗
║ PHASE 2: SURGICAL IMPLEMENTATION ║
╚═════════════════════════════════════════════════════╝
│
│ For each TODO item:
│
┌──────────┴──────────┐
│ │
▼ ▼
┌──────────────────┐ ┌───────────────────┐
│ 🦨⚡ SURGICAL- │ │ 🧪 TDD │
│ CODER │◄──┤ RED → GREEN → │
│ ├─ File paths │ │ REFACTOR │
│ │ from JSON │ │ ├─ Write test │
│ └─ Implement │ │ ├─ Min impl │
│ feature │ │ └─ Clean code │
└────────┬─────────┘ └─────────┬─────────┘
│ │
└───────┬───────────────┘
│ [Tight Loop]
│
│ If fails twice → 🔄 DEBUGGER
│
▼
[Repeat for all TODOs]
│
│ [CHECKPOINT: Code Validation]
│
▼
╔═════════════════════════════════════════════════════╗
║ PHASE 3: QUALITY FINALIZATION ║
╚═════════════════════════════════════════════════════╝
│
▼
┌──────────────────────────────────────┐
│ 🏆 QUALITY-PIPELINE-EXECUTOR │
│ ├─ PRE-EXECUTION: │
│ │ └─ Review git diff --staged │
│ ├─ PIPELINE: │
│ │ ├─ ./quality_gate.sh “msg” │
│ │ ├─ Lint (syntax + style) │
│ │ ├─ Tests (unit + integration) │
│ │ ├─ Security scans │
│ │ └─ Coverage checks │
│ └─ FAILURE HANDLING: │
│ ├─ TEST fail → 🔄 Debugger │
│ ├─ LINT fail → 🦨⚡ Code Agent │
│ ├─ GIT fail → 🔧 Git-Command │
│ └─ DEPLOY fail → 📦 DevOps │
└──────────────────┬───────────────────┘
│
▼
╔═════════════════════════════════════════════════════╗
║ PHASE 4: FINALIZE & INSIGHTS ║
╚═════════════════════════════════════════════════════╝
│
┌──────────┼──────────┐
│ │
▼ ▼
┌──────────────────┐ ┌──────────────────────┐
│ 📚 DOCS-WRITER │ │ 🧐 POSTMORTEM- │
│ Update docs │ │ ANALYST │
│ │ │ ├─ Task summary │
│ │ │ ├─ Solution overview │
│ │ │ └─ Key learnings │
└──────────────────┘ └──────────┬───────────┘
│
▼
✅ COMPLETE
My instructions were truly detailed. Here’s an excerpt from my Custom-Instructions-for-All-Modes:
The 5 Whys Principle is a root cause analysis technique. The essence of the method: when a problem arises, you ask the question “Why did this happen?” five times in a row, each time deepening from the symptom to the true cause.
This diagram shows the file operation protocol: each action goes through READ → VERIFY → DECLARE → APPLY → RE-READ. On error, “5 Whys” analysis launches to find the root cause, after three failures, escalation to human.
┌────────────────┐
│ TASK ARRIVES │
└───────┬────────┘
│
▼
┌─────────────────────────────┐
│ FILE INTERACTION PROTOCOL │
│ ─────────────────────── │
│ 1. READ → Load file │
│ 2. VERIFY → Check state │
│ 3. DECLARE → State intent │
│ 4. APPLY → Max 2 files │
│ 5. RE-READ → Verify │
└─────────┬───────────────────┘
│
┌─────────┴─────────┐
│ │
SUCCESS ERROR
│ │
│ ▼
│ ┌───────────────────────┐
│ │ ROOT CAUSE ANALYSIS │
│ │ Why? × 5 → ROOT_CAUSE │
│ └──────────┬────────────┘
│ │
│ ┌──────┴──────┐
│ FIX OK FIX FAILS
│ │ │
└───────────┘ ▼
┌──────────────────────┐
│ ESCALATION MATRIX │
│ ────────────── │
│ Strike 1: Retry │
│ Strike 2: Analyze │
│ Strike 3: → Human │
└──────────────────────┘
As you can see, I thought through everything: from complexity assessment and planning to the TDD cycle, automated Quality Gate, and insight collection after task completion.
What could go wrong?
On paper, my system looked perfect. But there was one problem I stubbornly ignored: I was building a complex orchestra of a dozen agents, where each had to flawlessly perform their role. The slightest failure of one link, and the entire chain collapsed. I believed that detailed prompts would protect me from chaos. Spoiler: they didn’t.
Harsh Reality: Uprising of Machines (and Tokens)
The ideal system began to fail, turning my dream into an expensive nightmare.
File editing errors were constant. I kept getting errors like
“Edit Unsuccessful”or“Kilo Code tried to use apply_diff without value...”. Agents simply couldn’t reliably edit files. I tried to solve this with even more detailed instructions, but to no avail.Infinite loops plagued the system. I literally watched as the coder agent entered a paralyzing cycle: read file -> make a change to one line -> read the entire file again for verification -> make a change to the next line. This was a consequence of my own instruction to “make precise, surgical changes to avoid errors”. Token consumption flew into space, and a simple task stretched out for dozens of minutes.
Loss of control emerged frequently. Sometimes an agent got so “carried away” with developing one feature from the list that it continued working on it for hours, completely ignoring other tasks, until I forcibly stopped it. It started inventing subtasks that weren’t in the plan.
“Phantom execution” was the most disappointing. The most frustrating thing was when my complex orchestrator, receiving a report from the planner agent (
docs-writer), immediately reported: “Task completed!”, without even starting to write code. It took the completion of planning as full completion of the entire mission.
My work turned from development into endless prompt debugging. I made them even more detailed, even stricter, but it was like putting out a fire with gasoline.
First Insight: The Problem Wasn’t in the Prompt
In desperation, I wrote a post on Reddit. I was advised that experimental features in tools can cause unpredictable behavior.
I opened Kilo Code settings and without much hope disabled two checkboxes in the “Experimental” tab: Enable concurrent file edits and Background editing. Later I completely disabled all experimental features that only inflated the instruction and agent complexity.
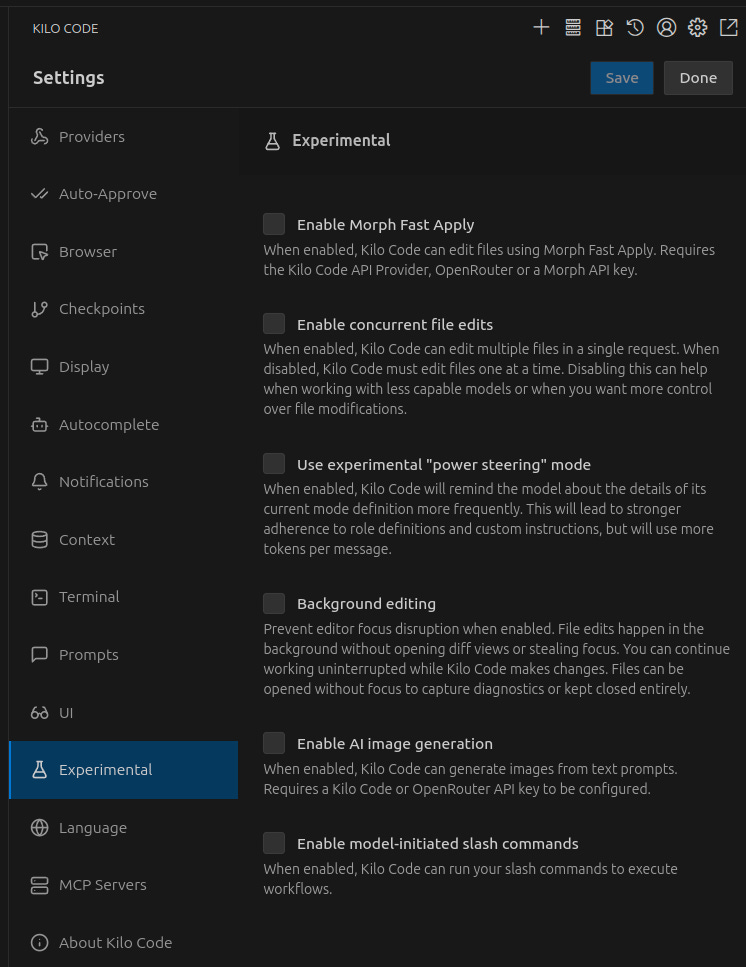
And, miraculously, file editing problems decreased by 90%
At that moment I felt a mixture of relief and deep bewilderment. I had spent weeks refining prompts, and the solution was in two checkboxes. Why are these options even available if in most cases they worsen model behavior? I was disappointed that experimental improvements turned out to be unnecessary, and I would have to work with old but stable approaches. This was the first bell: perhaps I was looking for a solution in the wrong place.
Second Insight: Disappointment and Revelation
Inspired by success, I decided to go further. If disabling “improvements” in the tool helped, what if I disabled my own “improvements”, my super-detailed prompts? Moreover, I was prompted by another Reddit post that screamed: “We take the most powerful reasoning engines and lobotomize them with middleware... The model spends 70% of the window reading garbage, instead of studying the task.”
With a heavy heart, I rolled back all my hard-won prompts to basic settings. I launched the same task. And...
Practically nothing changed.
The basic, “dumb” system without my complex workflows and detailed instructions worked almost the same. Yes, the agent was still unhurried, but there were no more critical errors.
That’s when I became truly disheartened. Upset about the wasted time, about the effort put into selecting each word in the prompts. I was simultaneously happy that I found a simpler path, and disappointed, realizing that most of my work was practically useless.
Conclusions: My New Rules of “Vibe Coding”
This painful experience taught me several important things.
Perfect is the enemy of good. The entire field of AI assistants is still very new. My complex system of a dozen agents was excessive. Simplicity sometimes works better.
We must trust smart models more, giving them space for creativity, not limiting them with strict but fragile instructions.
Reliable
if/elseis better than an unreliable agent. Simple, deterministic workflows should be solved with scripts. I realized that myquality_gate.shwas the most reliable part of the system. Running tests, linters, and making commits is a task for bash, not for LLM. Agents should do what they do best: be creative, brainstorm, and think, not blindly follow procedures.In practice, powerful models can confidently rewrite entire files at once, although if you ask them for super high-quality production code, they are indeed prone to excessive refactoring and complicating code with unnecessary features, violating the KISS principle.
How I Work Now (Spoiler: Simply)
Today my workflow looks like this: I brainstorm architecture in chat with a powerful model, then create a basic plan literally with arrows and pseudocode to describe how everything should work as meticulously as possible. After that, I give the task to one coder agent with minimal instructions in Kilo Code, controlling its work after each major change. The entire CI/CD process is launched with one bash script. This isn’t as “autonomous” as I dreamed, but it works, saves tokens, and most importantly, my nerves.
My quality_gate.sh remains the only reliable part of the entire system. This is a simple bash script of about 100 lines that sequentially runs:
Runs pytest (backend tests).
Runs pre-commit hooks (black, mypy, vulture, pyupgrade, sourcery...).
Runs frontend build.
Runs frontend tests.
Runs frontend dev-server.
Runs deployment, collects logs for 2 minutes.
Does git add and commit.
No LLMs, no prompts, just reliable if/else. This worked flawlessly, unlike my entire army of agents.
For small projects, I wrote a script that uses repomix to collect the entire repository into one text file. The agent reads it in one request and immediately understands the entire project structure, which simplifies logic and speeds up understanding. This is profitable if you are limited by the number of requests, but can be expensive if you pay per token. For large projects, you can use a similar approach, but use code not from the entire project, but from a module.
I will definitely return forced test execution after every code change to my workflow, as done in aider. This allows catching errors immediately, not after hours of agent work, when it’s already unclear what exactly broke.
I also discovered that in system development it’s extremely important to get feedback about code operation as early as possible. If backend work is tested fairly simply, with frontend things are more complex. I plan to implement in my system taking screenshots and extracting logs from the browser console to launch and catch errors after implementing each feature. It would be great if the agent wrote selenium code and tested the frontend for actions.
What’s Next: In Search of “Orchestrator Over Orchestrator”
I haven’t abandoned the idea of automation, but my approach has changed. I continue to experiment, looking for that very balance between control and freedom for AI.
I dream of an “orchestrator over orchestrator”. This could be another, more powerful AI supervisor that would take on the role of “human in the loop”. When the coder agent asks: “What approach is better to use?” or asks to make an architectural decision, this supervisor could conduct a quick search, brainstorm, and give an answer. And for humans would remain only the most abstract, meta-questions directly related to business logic.
Perhaps the future is not in an army of narrowly specialized bots, but in a smart tandem: one powerful AI supervisor and one AI executor, working under careful but minimal human control.
What about you? Have you encountered similar problems when working with AI agents? Maybe you have your own life hacks for setting up prompts or workflows? Or am I the only one who spent a month building a complex system, only to return to a simple bash script? Share your experience in the comments. I’m interested to know how others solve the “human in the loop” problem!
In this blog, I report on my improvement in this area. Perhaps someday I will find or create that very “perfect prompt” or perfect workflow.